- A line chart with X as time and Y as 3 lines of x, y, z acceleration
- A 3d plot of x, y, z acceleration with color being the sample time
Is interesting to see the actual sensor fidelity in a visual form. CMSensorRecorder records at 50 samples per second and the visualizations are 400 samples or 8 seconds of data.
You can try out the sample here at http://test.accelero.com There are a couple of suggested start times shown on the page. Enter a time and hit the Fetch button. Recall this fetch button allows the browser to directly query DynamoDB for the sample results. In this case anonymously and hard coded to this particular user's Cognito Id...
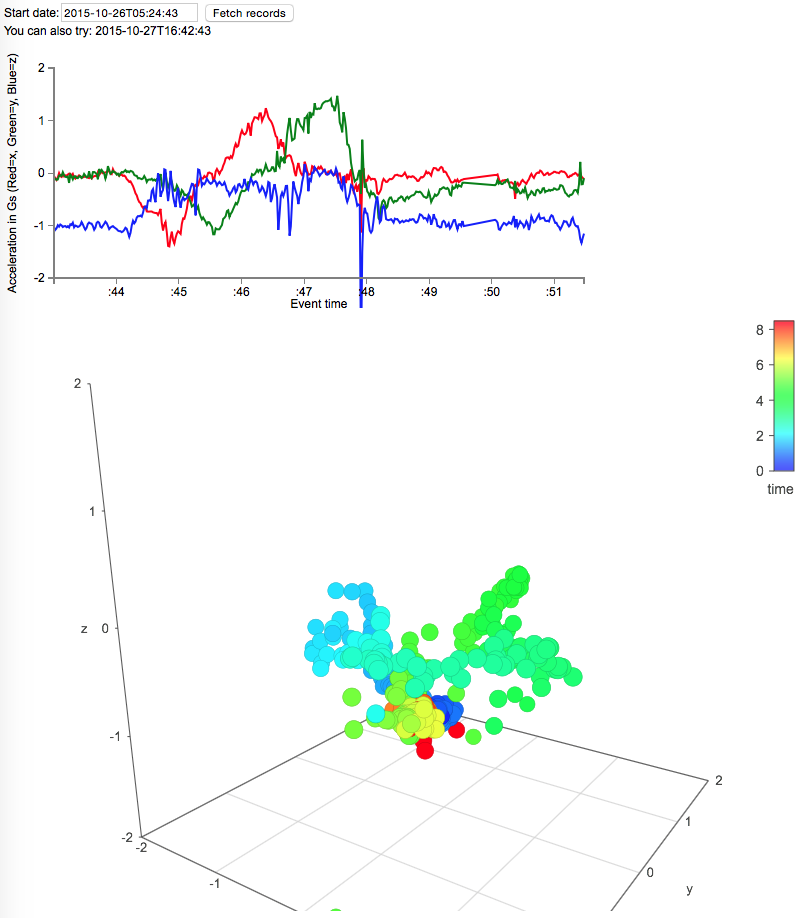
Once the results are shown you should be able to drag around on the 3d plot to see the acceleration over time.
The above timeslice is a short sample where the watch starts flat and is rotated 90 degrees in a few steps. If you try out the second sample you will see a recording of a more circular motion of the watch.
Note that d3.js is used for the line charts and vis.js is used for the interactive 3d plot.




